DEPARTAMENTO DE INTELIGENCIA ARTIFICIAL Asignatura: Introducción a la Inteligencia Artificial |
|
||
| >> Introducción a la Inteligencia Artificial >> Bibliografía básica >> Materia | ||
MATERIA DE LA ASIGNATURA
La materia objeto del presente análisis trata de la "Inteligencia Artificial", y esto no sólo se refiere a la forma actual de llevar a cabo la mecanización de los procesos del pensamiento: los programas de computadores, sino a todos los intentos de construir sistemas o autómatas inteligentes realizados a lo largo de la historia. Analicemos por tanto en primer lugar sus antecedentes.
Como en cualquier otra rama del saber, existen multitud de circunstancias a lo largo de la historia que han conducido a la situación actual. Puede decirse que desde siempre el ser humano ha tenido presente el "desafío del hombre que fabrica al hombre". Como manifestaciones más remotas de este deseo podemos destacar: las figuras utilizadas en los ritos de magia del hombre primitivo, las estatuas que servían de cobijo a los muertos en la cultura egipcia; los artilugios diversos (p.ej. maquinarias escénicas) que se inventaron en la época alejandrina de la Grecia Clásica; y la que parece haber sido la primera referencia a un androide, Talos, obra de Dédalo, gigantesco robot de la mitología que protegía a Creta de sus enemigos.
Mucho más cercano, en el siglo XIII podemos mencionar la existencia de una leyenda en la que se describía la construcción de una "cabeza de bronce pensante" que explicaba a fray Roger Bacon y a su colega fray Bungey como defender Inglaterra con una gran muralla de bronce. También existen historias sobre la construcción de "cabezas parlantes" por Alberto Magno, Tomás de Aquino, el obispo Grosseteste, el papa Silvestre II, etc. Como siguiente antecedente no debemos olvidar, el que para muchos es el verdadero paradigma de la Inteligencia Artificial: El Glem (palabra talmúdica que se refiere a todo lo incompleto o sin forma) que el rabino Judah Loew construyó en 1580 y que consistía en una estatuilla que cobró vida y sirvió para defender a la comunidad judía de Praga, aunque luego tuvo que ser destruido cuando éste perdió el control y se convirtió en "un monstruo que amenazaba al mundo". En el mismo siglo XVI, como un ejemplo más del desarrollo de la alquimia de la época, el médico medieval Paracelso llegó a elaborar la receta para crear un "homúnculo": un ser humano entero artificial.
Todos los ejemplos mencionados pertenecen al mundo de las leyendas y no existen indicios de ningún medio técnico para su creación. Los primeros hombres mecánicos fueron las figuras móviles de los campanarios de finales de la Edad Media. Existen otros relatos que hablan de seres artificiales construidos por Leonardo da Vinci y posteriormente Descartes. Posteriormente, la máchina arithmetica de Pascal de 1645 era capaz de realizar sumas y restas mediante un engranaje con ruedas dentadas. Leibniz amplío en 1670 el rango de operaciones realizables (multiplicar y dividir). El siguiente caso más claro de mecanismos autónomos lo encontramos en los relojes de gran precisión construidos en el siglo XVIII. De este mismo siglo data la historia del jugador de ajedrez falso construido por Wolfgang von Kempelen: la primera vez que se creaba la ilusión de no distinguir las capacidades de un hombre frente a las de una máquina. Otro androide, en este caso un músico, lo construyó Jaquet-Droz (se encuentra en el Museo de Arte e Historia Natural de Suiza). Más recientemente, la Revolución Industrial potenció la creación de máquinas herramientas, siendo en este contexto cuando surgió la idea del computador digital llamado "Aparato Analítico" de Charles Babbage, con una visión mucho más cercana a lo que hoy consideramos rasgos propios de esta rama del saber (por ejemplo, una máquina que sea capaz de tomar sus propias decisiones) Después, tal y como ya analizamos en el apartado 1.5.1, se produce la sorprendente evolución de la informática a lo largo del siglo XX. Una de las primeras contribuciones de comienzos del siglo fue la máquina de jugar a la ajedrez de Leonardo Torres y Quevedo en 1912, con capacidad de tomar decisiones y no sólo de tratar la información. Después nos encontramos -estimulado por la segunda guerra mundial- con los tiempos del florecimiento de los grandes computadores (el Colussus de Turing, el Edvac de Von Neuman, el Eniacà). En esta misma época se produjo un enorme impulso en el campo del control automático (mecanismos que se guían solos), que finalmente ha dado lugar a los robots programables que hoy podemos ver en cualquier fábrica o taller industrial.
Una vez creadas estas máquinas era el turno de los que fueran capaces de programarlas, y esta fue precisamente la época en que comenzó la historia más reciente de la Informática en general y de la Inteligencia Artificial en particular. Podemos destacar los trabajos de Shannon que, además de otras muchas aportaciones (diseño de circuitos, transmisión digital de señales, etc.), escribió en 1950 el artículo "Una máquina para jugar al ajedrez" en el que predecía que los computadores podrían jugar bien a este juego, estudiando un gran número de jugadas y sus consecuencias, para así luego escoger la más prometedora. Con este mismo enfoque, en 1959, Samuel realizó el primer programa que aprendía a jugar a las damas. Los trabajos de Shannon fueron también una importante contribución para los nacientes campos de la teoría de la información y del control, que Norber Wiener llamó cibernética. Surgieron paralelamente los primeros estudios formales sobre redes neuronales formales, inspirados en el propio ser humano, entre los que destaca el primer modelo de computación analógico no lineal y distribuido diseñado por W.S. McCulloch y Walter Pitts (1943), que luego fue mejorado y ampliado en sucesivas ocasiones, por Blum (1955), por Rosenblatt (1962), y por Widrow y Hoff (1969). Básicamente, la propuesta consistía en que cualquier ley de entrada-salida podía modelizarse con una red neuronal: redes de elementos de procesamiento analógico no lineal (sumadores con pesos modificables seguidos de una función de decisión no lineal de tipo umbral) inspirados en algunos aspectos superficiales del funcionamiento de las neuronas.
El verdadero surgir del término "Inteligencia Artificial" (acuñado por John McCarthy) tuvo lugar en el estudio sobre el tema realizado - bajo el auspicio de la Fundación Rockefeller - por diez personas durante dos meses en el "Darmouth College", en el verano de 1956. Entre los invitados destacan personajes tan eminentes como: McCarthy, Samuel, Minsky, Newell, Shaw y, el que sería más tarde premio Nobel, Simon. La evolución experimentada desde los primeros modelos neuronales hasta la situación actual puede dividirse en una serie de etapas:
Como ya hemos señalado, la Inteligencia Artificial (IA) comenzó siendo computación neuronal con los trabajos de McCulloch y Pitts, que introdujeron la idea de circuito secuencial mínimo, formado por una función lógica seguida de un retardo y en el que la programación se sustituye por el aprendizaje.
Los trabajos de esta época, a la que puede denominarse neurocibernética, se basan en crear modelos formales que sigan los mismos principios de funcionamiento que tienen las componentes conocidas de los organismos biológicos en los que descansa la facultad de pensar del ser humano. Por tanto, tomando como ejemplo las neuronas del cerebro se crean modelos que sean capaces de: crear una memoria asociativa, autoorganizarse y aprender de forma autónoma.
En este período se busca la solución de los problemas en un nivel físico, donde una función se realiza por una sola estructura (p.ej., un sumador "suma"). Así, la estructura de las neuronas formales de la primera época consistía simplemente en una serie de entradas, que podían ser excitadoras o inhibidoras, y en una función umbral (con un nivel de disparo) sobre la suma de dichos estímulos. Estas unidades formaban una red que definía una u otra función según fueran los umbrales de disparo y la disposición de las conexiones entre ellas.
Podemos destacar tres ideas básicas de la etapa neurocibernética: la noción de información como pura forma, separable de la señal física que la transporta, apoyada por los trabajos de Rosemblueth, Wiener y Bigelow sobre "Conducta, Propósito y Teología", y los de Shannon; la Teoría Neural del Conocimiento, basada en redes de procesadores que sean capaces de: reconocer caracteres, recordar, inferir de forma distribuida, cooperar, aprender por refuerzo o autoorganizarse; y finalmente, la Representación Interna del Medio, que considera al sistema nervioso como un constructor de dicha representación, con el fin de definir operacionalmente conceptos tales como: causalidad, significado, implicación y consistencia. Con esta última idea como base, la propuesta de un mecanismo de razonamiento por analogía de Craik es un claro antecedente de los trabajos más actuales sobre el razonamiento abductivo (razonamiento en que se parte de la conclusión y se busca un hecho que la explique).
El reconocimiento del valor limitado de los modelos aplicados produjo un abandono generalizado de este enfoque (lo cual no excluye que investigadores relevantes siguieran trabajando sobre el tema), hasta que en los años ochenta se produjo un resurgir que se ha mantenido hasta nuestros días.
Se considera que el punto de partida de este período es la citada reunión en el verano de 1956, propuesta por McCarthy, Shannon y Marvin. Desde el punto de vista de los objetivos que se intentaban resolver, en esta época se seguía queriendo afrontar problemas muy complejos con formulaciones relativamente simples. En lo que se refiere al enfoque práctico -cómo resolverlos-, la principal característica del modelo adoptado en este período es la utilización del cálculo simbólico, frente al numérico que caracterizó la etapa anterior. Por ello, puede ser clarificador repasar, aunque sea brevemente, algunos antecedentes de este paradigma.
La existencia de modelos formales para representar el razonamiento, la posibilidad de manipular dichos formalismos mediante un conjunto finito de reglas de transformación, y los avances en la teoría de la computación, fueron las principales bazas que utilizaron Allen Newell y Herbert Simon para desarrollar el sistema que se considera el origen del razonamiento automático, el Teórico Lógico. Este programa, que podía demostrar los teoremas del Principia Mathematica -la obra central de los fundamentos de las matemáticas escrita por Bertrand Russell y Alfred North Whitehead-, fue capaz de sorprender a los propios Russell y Whitehead inventando una demostración más breve para uno de los teoremas propuestos. Estos mismos científicos, junto con Cliff Shaw, construyeron el denominado "Solucionador General de Problemas" (GPS), así denominado por ser capaz de plantear de una forma genérica la solución de problemas. La aportación fundamental del GPS es el esquema denominado análisis de medios-fines, que consiste básicamente en saber donde se está, compararlo con aquello que se quiere alcanzar, y buscar maneras de reducir las diferencias entre ambos. El planteamiento es bastante intuitivo y responde a modelos de actuación tratados en el campo de la psicología cognitiva. Una aportación implícita, y muy importante de este modelo, es la idea de que puede distinguirse el conocimiento sobre un problema concreto del saber más general sobre cómo pueden resolverse un conjunto de problemas. En otras palabras, consiste en separar el conocimiento de control del conocimiento del dominio.
Los problemas resueltos podrían calificarse "de laboratorio": planteamientos simplificados de problemas complejos o modelos de problemas perfectamente definidos. Tales son los casos de los juegos (ajedrez, damas, puzzles, tic-tac-toe, ocho reinas, etc.) y de la demostración de teoremas del cálculo proposicional. Para resolverlos se adoptó un esquema conocido como "búsqueda en un espacio de estados", que consiste básicamente en transformar un problema o estado inicial en una meta o estado final a través de la aplicación de una secuencia de operadores o reglas que describen las acciones del dominio siguiendo una determinada estrategia de selección de dichos operadores y de los estados generados en el proceso de búsqueda. En este esquema la solución consiste en una secuencia de operadores que permiten pasar del estado inicial al estado final.
Un avance muy significativo del campo lo produjo el desarrollo de nuevos lenguajes de programación. De este período el más destacado es el LISP (es el segundo lenguaje más antiguo, después del FORTRAN, que sigue utilizándose como lenguaje básico para realizar investigación en IA), diseñado para manipular los símbolos -elementos propios de una representación del conocimiento-. Este lenguaje se creó a mediados de los años 50 en el laboratorio de Inteligencia Artificial del MIT (Massachusetts Institute of Technology), su creador principal fue John McCarthy. Era el primer lenguaje de programación que permitía la definición de funciones recursivas. De su larga historia podemos destacar que, en esta primera época (LISP 1.5), consistía en un lenguaje poco evolucionado con unas 100 primitivas. Su diversificación se produjo en los años 70 y su divulgación y estandarización en los 80 (COMMON LISP).
En esta época se establecen también las bases que permitirían crear algunos años después (1972) otro de los lenguajes básicos del campo, el PROLOG. En los años 60 varios "logicistas" y matemáticos buscaban algún método que permitiera que los computadores llevaran a cabo la prueba de teoremas. Algunos programas permitían ya realizar pruebas de teoremas sencillos utilizando la instanciación de Herbrand; pero fue el principio de resolución el que sentaría definitivamente los pilares de la programación lógica, permitiendo deducir nuevos hechos y relaciones a partir de los enunciados dados, en lugar de trabajar con instanciaciones triviales de aquéllos.
Otro de los problemas complejos que se pretendía resolver fue el del procesamiento del lenguaje natural (LN), cuyo objeto de estudio son los mecanismos efectivos y computables para llevar a cabo procesos de comunicación basados en LN. Esta rama de la IA está íntimamente relacionada con otras disciplinas: lingüística y psicología cognitiva; la primera estudia modelos generales que reflejen la estructura del LN sin preocuparse de su realización en procesos computables (p.ej., el modelo más conocido, propuesto por Chomsky, no es apto para ser implementado); la segunda se ocupa más bien de modelos sobre el uso del lenguaje; por lo tanto, más cercanos a los propósitos de la IA sobre esta cuestión. Dentro de este campo debemos distinguir dos áreas de gran interés: la traducción automática (TA) y la comprensión del lenguaje natural (CLN).
El antecedente más inmediato de la TA lo encontramos en el desarrollo espectacular de los métodos criptográficos a raíz de la segunda guerra mundial. El presidente de la fundación Rockefeller, Warren Weaver, fue el principal impulsor de la perspectiva criptográfica, que se considera el origen de este campo. Por otro lado, los estudios de la época pusieron de manifiesto las que siguen siendo, principales cuestiones por resolver: análisis sintáctico y morfológico, resolución de homografías, representación interlingua del significado, estudios sobre vocabularios restringidos, búsqueda automática en diccionarios, etc. La primera conferencia sobre el tema tuvo lugar en el MIT en 1952, y la primera demostración pública de un programa de traducción automática tuvo lugar en 1954 en la Universidad de Georgetown. El experimento consistió en traducir al inglés 50 sentencias en ruso seleccionadas de textos de química. Supuso una demostración de las posibilidades del campo y fue un estímulo para el desarrollo de nuevas investigaciones sobre el tema. No obstante, la subestimación de los problemas existentes; por ejemplo, la ambigüedad léxica, terminó produciendo un cierto desencanto, que en 1964 se tradujo en la emisión del informe ALPAC por la Academia de las Ciencias Americana, en el cual se aconsejaba una reducción drástica en las subvenciones previstas.
Dos razones fundamentales pueden aducirse para entender el interés en el campo de la CLN. En primer lugar: las bases de datos, los paquetes de software y las aplicaciones de IA, requieren interfaces cada vez más flexibles y adaptados a cualquier usuario. La segunda razón de peso es la trascendencia que dicho proceso tiene en el comportamiento inteligente. Dado que la solución del problema de la CLN estaba muy lejos de poderse afrontar, se optó, en algún caso, por "esquivar" el problema. Este es precisamente el planteamiento de uno de los primeros programas lingüísticos más conocidos: ELIZA (su nombre es el mismo que el de la protagonista de My Fair Lady, que tuvo que aprender a hablar correctamente el inglés), creado por Joseph Weitzenbaum en 1966. Este programa, basado en la "equiparación de patrones" (pattern matching), simulaba una conversación con el usuario utilizando palabras que éste había nombrado como base de las frases y preguntas que él formulaba, o proponiendo frases poco comprometidas como: "Cuéntame más sobre esto, por favor". Realmente, cualquiera que se haya enfrentado al programa sin previo aviso puede llegar a pensar que está manteniendo una conversación con un interlocutor bastante "razonable", por no decir "inteligente".
La CLN se afrontó desde múltiples perspectivas. Algunos de los trabajos más significativos se reúnen en el libro "Procesado de Información Semántica". Esta recopilación contiene algunos de los trabajos más representativos de la época, que fueron el resultado de tesis doctorales dirigidas por el propio Minsky en el MIT: SIR de Raphael, STUDENT de Bobrow, redes semánticas de Quillian, ANALOGY de Evans, BLACK (sistema deductivo de contestar preguntas), y programas sobre el problema del "sentido común" de McCarthy. Un sistema que alcanzó unas prestaciones sorprendentes para esa época fue SHRDLU; estaba basado en el antiguo esquema consistente en separar el análisis sintáctico del semántico; otra particularidad es que el conocimiento del problema se representaba de forma procedimental. Una aportación especialmente significativa fueron las "Redes de Transición Ampliadas" (Augmented Transition Networks: ATN), cuya notación gráfica recuerda a la de una máquina de estados finitos en la que se ha ampliado el tipo de etiquetas que se pueden asociar a los arcos que definen las transiciones (cada una supone realizar una comprobación para poder atravesar el arco); estas redes, basadas en el análisis sintáctico, tienen como principales inconvenientes: su complejidad y su falta de modularidad -son muy sensibles ante pequeños cambios-.
El problema de la CLN forma parte de un problema más general, la comprensión. No debe sorprendernos que muchas de las técnicas aplicadas en aquél sean también útiles en otro de los campos existentes, el Reconocimiento de Imágenes; al fin y al cabo, en ambos problemas se trata de transformar una representación en otra. En este área se logró, por primera vez, estructurar los diferentes componentes de un sistema de visión: extraer las características de la imagen (en este caso, líneas), activar el modelo correspondiente a dichas características, proyectar el modelo previsto en una imagen, y finalmente, elegir el mejor modelo en función de su grado de semejanza con los datos. En este esquema no se tenía en cuenta la presencia del ruido, que sí pudo tratarse más adelante en INTERPRET.
Por otro lado, una vez se creía superado el enfoque neurocibernético del problema del aprendizaje, se crearon los primeros sistemas que lo afrontaban desde una perspectiva simbólica. El hecho más destacado fue el desarrollo de un programa que era capaz de aprender a jugar a las damas lo suficientemente bien como para batir a su creador. Este sistema utilizaba dos clases de aprendizaje: memorístico (almacenar valores calculados de información para que no sea necesario volver a calcularlos más tarde) y ajuste de parámetros o de coeficientes. Este último consiste en combinar la información recibida de diferentes fuentes para formar un único resumen estadístico, en este contexto denominado función de evaluación: cuyo valor es una combinación lineal de 16 factores (p.ej., movilidad de las piezas) con sus respectivos coeficientes o pesos. El aprendizaje se traduce en el incremento o disminución de los pesos dependiendo de que el factor correspondiente afecte a la variación experimentada en el valor de la función a lo largo del juego. Como puede apreciarse, este tipo de análisis es bastante limitado ya que no se tiene en cuenta el conocimiento implicado ni la estructura y las relaciones del mismo en el dominio. En cierto sentido, este aprendizaje sigue siendo más numérico que simbólico.
Con la intención de mejorar los resultados, se empezaron a incorporar en los esquemas generales de la etapa previa los conocimientos que dependían del problema. Consecuentemente, dado que el problema afrontado era ya de un tipo concreto, se llegó a generalizar el uso de técnicas que tuvieran en cuenta el conocimiento específico de cada uno de ellos.
Una de las primeras aportaciones de este período es la clarificación sobre la naturaleza de las técnicas de representación del conocimiento. El dilema es el siguiente: Ante cualquier problema se presentan dos situaciones posibles: saber de antemano el conocimiento sobre lo que hay que hacer o tener que indagar qué podría hacerse para resolverlo. Las técnicas de representación que permiten describir los aspectos conocidos del problema se denominan declarativas (p.ej., programación lógica, redes asociativas y reglas). Las que se centran en especificar el proceso que hay que realizar para encontrar las soluciones buscadas se denominan procedimentales (p.ej., funciones LISP). La conclusión de esta etapa es que lo adecuado en problemas complejos consiste en combinar técnicas (lógica, reglas, marcos, redes asociativas, etc.) de ambas naturalezas; además, en sentido estricto, no existen técnicas puramente procedimentales o declarativas (p.ej., en PROLOG es importante el orden de declaración de los enunciados).
Otro rasgo distintivo de la época es la utilización de métodos heurísticos. En principio, la IA tiene por objeto el estudio de los problemas que no tienen una solución analítica o que, aun existiendo ésta, no puede calcularse con los recursos computacionales disponibles. La heurística sería el conjunto de procedimientos basados en conocimiento del dominio que permiten solucionar el problema con los recursos disponibles pero con una reducción asumible en la calidad de las respuestas. Por tanto, la clave estriba en encontrar un equilibrio entre el conocimiento del dominio, el coste de cálculo, y la bondad del resultado. Inicialmente, las heurísticas se aplicaban en forma de funciones numéricas que guiaban procesos de búsqueda. Lenat amplió su significado al contexto de las reglas de producción (explicadas un poco más adelante) desarrollando un sistema, Eurisco, capaz de aprender reglas que establecen la relación de oportunidad o adecuación entre situaciones y acciones.
Un hecho destacable en los comienzos de este período fue el desarrollo de los métodos teóricos que finalmente permitieron llevar a cabo de forma efectiva la programación lógica; entendida como el uso de lógica para representar problemas y métodos de solucionarlos, junto con la utilización de procedimientos apropiados de prueba para la solución real de dichos problemas. Lo que hizo posible el desarrollo de este campo fueron las técnicas de extracción de respuestas de los procesos de resolución y su realización computacional (para finales del verano del 72 ya estaba disponible la primera versión del PROLOG, Programmation en Logique. La importancia de este campo se refleja en su adopción como base del proyecto Sistemas de Computadores de Quinta Generación.
Esta época se caracterizó por la exploración, sobre todo al principio, de diferentes formas de representación del conocimiento e inferencia: sistemas de producción, redes asociativas (semánticas, de clasificación, causales (p.ej., CASNET), bayesianas, grafos proposicionalesà), marcos (creados inicialmente para afrontar el "razonamiento basado en el sentido común"), programación declarativa (p.ej., PROLOG), programación funcional (p.ej., MIRANDA), multitud de versiones de LISP (p.ej., SCHEME, INTERLISP) que incorporaban estas y otras ideas (p.ej. FLAVORS), programación orientada a objetos (p.ej., SMALLTALK, LOOPS, CLOS), etc.
El modelo imperante en esta época eran los Sistemas Basados en Reglas (SBR). Éstos se enmarcan dentro de los Sistemas Basados en el Conocimiento (SBC), también llamados Sistemas Expertos, por compendiar el conocimiento sobre un tema concreto o por emular el comportamiento de un experto en un dominio. Esta nomenclatura es claramente imprecisa, ya que hay otras muchas formas de representar el conocimiento o de sintetizar el conocimiento de un experto. La esencia de este modelo consiste en suponer que el conocimiento es algo "parcelable", formado por relaciones sencillas de causalidad o de secuencialidad: "Si tal Entonces cual" (o si se prefiere, "Cuando situación Entonces acción"), que pueden recuperarse cuando son necesarias cuando se pregunta por tal o por cual. El razonamiento realizado consiste en enlazar los fragmentos que tengan tales ("encadenamiento hacia adelante") o cuales ("encadenamiento hacia atrás") coincidentes (en realidad la coincidencia puede ser parcial; por ejemplo, que ambos pertenezcan a la misma categoría). Sobre este esquema básico y para que el sistema sea eficiente, se agrupan dichos fragmentos por temas (conjuntos de reglas); se ordenan los fragmentos aplicables por diferentes criterios (p.ej. los patrocinadores en GoldWorks); se crean redes que permiten apuntar casi instantáneamente a los tales que dependen de los cuales o viceversa (p.ej. RETE en OPS5), para así evitar tener que recorrer numerosas veces el almacén de todos los fragmentos; se crean fragmentos que hacen referencia a otros fragmentos (metarreglas en TEIRESIAS), en lugar de apuntar al conocimiento del dominio; se escogen los fragmentos que tengan que ver con los últimos tales o cuales generados (p.ej., mecanismos de "actualidad" en OPS5); se prefieren los fragmentos que tengan un mayor número de tales o cuales semejantes a los tales y cuales de la pregunta formulada (p.ej., mecanismos de "especificidad" en OPS5); etc. En los sistemas que utilizan este modelo se distinguen una serie de componentes: a la parte del sistema encargada de gestionar y enlazar todos estos fragmentos se le denomina Motor de Inferencias; al conjunto de fragmentos se le denomina Base de Conocimientos; y a los procesos que hacen posible la interacción entre el usuario y el sistema se le conoce por Interfaz de Usuario.
El esquema de funcionamiento de la mayoría de los SBR de la época era el denominado Sistema de Producción, caracterizados por que la "comunicación" entre las reglas se realiza a través de una base de datos, también llamada memoria de trabajo, en la que se guardan los elementos de información que constituyen los datos iniciales y los elementos que se van paulatinamente referenciando en las reglas utilizadas a partir de dichos datos. Esta base puede ser tan simple como una lista o tan compleja como una red de marcos (p.ej., Hersay-II). Cuando hay más de una regla aplicable ("equiparable" con los datos de la base) se produce un "conflicto" que puede resolverse siguiendo diferentes criterios: el sistema MYCIN simplemente ejecuta todas las reglas; otros, como el mencionado OPS-5, tienen un amplio conjunto de heurísticas que prefieren las reglas más recientes y más complejas (o específicas).
Otro de los esquemas imperantes fueron los marcos mencionados previamente. Aunque a primera vista pueda parecer que los marcos, y también los guiones, rompen el esquema básico de parcelación del conocimiento de los SBR, una reflexión más pausada nos indica que siguen siendo estructuras que aglutinan el conocimiento en fragmentos con una estructura estática y con unas posibilidades de relación entre sus partes también prefijadas. Siguen por tanto siendo parcelas de conocimiento, aunque de mayor tamaño y con nuevos matices. El objetivo de estos mecanismos de representación es poder plasmar situaciones estereotipadas, estructurando cada fragmento en una serie de campos (o escenas, en el caso de los guiones), de tal forma que son útiles en dominios tan diversos como: razonamiento basado en el sentido común, reconocimiento de formas, comprensión del lenguaje natural, diagnóstico médico, etc. El mecanismo de inferencia en este caso es la propia red de marcos, denominada red de activación. Por ejemplo, en el sistema experto PIP (comentado más adelante) cada enfermedad viene representada por un marco, la tarea de diagnóstico consiste básicamente en activar los marcos que representan los diagnósticos que incluyen algunos de los síntomas o signos observados en el paciente. Los marcos vecinos de un marco activado pasan a estar semiactivos, por lo que posteriormente podrán ser evaluados cuando se reciba nueva información. limitando así el espacio de búsqueda considerado. Una vez superada la fase de recogida de información, el sistema procede a evaluar los posibles diagnósticos (hipótesis generadas), con el objetivo de encontrar el que explique mejor la evidencia disponible. Por lo tanto, estamos ante un proceso de reconocimiento similar a los que pudieran darse en visión artificial o en la comprensión del lenguaje natural.
La capacidad de las reglas para representar los hechos del conocimiento del dominio, y la de los marcos para estructurar los objetos, sus relaciones, y las inferencias que dependan de éstas, terminaron por imponer un enfoque de construcción de los SBC basado en la combinación de ambas técnicas. A este modelo básico se le aplicaron mejoras tendentes a soslayar las dificultades en el tratamiento de la incertidumbre.
Dejando un poco de lado las cuestiones metodológicas y bajando al campo de las realizaciones prácticas, sería interminable dar una visión razonable del número y el rango de sistemas expertos (SE) construidos (no necesariamente SBR) o de las herramientas (en algunos casos, otros SE) utilizadas en su desarrollo (p.ej., EMYCIN, TEIRESIAS, S.1, M.1, HEARSAY-III, BB1, OPS5, OPS7, OPS83, ART, KEE, KNOWLEDGE CRAFT, UNITS, NEXPERT, etc.). No obstante, también sería imperdonable en este breve repaso histórico no mencionar algunos de los más significativos: PIP (present illness program), diseñado en base a una red de marcos para el diagnóstico de enfermedades renales; DENDRAL (y su ampliación Meta-DENDRAL), conocido como el primer SBR, sus reglas de producción se utilizaban para generar estructuras químicas que explicaran los resultados espectográficos; MYCIN fue uno de los primeros sistemas que eran capaces de explicar el razonamiento, lo cual es especialmente útil en su campo de aplicación, la medicina (más concretamente, el del diagnóstico y tratamiento de enfermedades infecciosas), su importancia la acredita la serie de sistemas construidos a partir de él (GUIDON -usa la base de conocimientos de MYCIN para construir un sistema tutor para instruir a los alumnos sobre enfermedades infecciosas-; EMYCIN -realizado a partir de los mecanismos de inferencia de MYCIN-; NEOMYCIN -separa el conocimiento estratégico en un conjunto de metarreglas-); CASNET, primer SE basado en una red causal, su nombre procede de Causal Associatonial Network, pretendía ayudar a los médicos en el tratamiento del glaucoma (enfermedad ocular); PROSPECTOR destinado a la exploración geológica, tuvo un gran éxito comercial al igual que XCON (uno de los primeros sistemas de diseño), utilizado por Digital Equipment Corporation para configurar sus estaciones de trabajo; ONCOCIN (también denominado R1), es el primer consejero de terapia en oncología y es una referencia obligada del razonamiento temporal; TAXMAN II sistema para el análisis de casos legales; ROSS, una herramienta orientada a objetos para el desarrollo de simulaciones basadas en el conocimiento; TWIRL, simulación de combate aéreo estratégico; ECAT, diseñado para ayudar a los químicos en el desarrollo de métodos de cromatografía para líquidos; INFERNO y AL/X, herramientas para el desarrollo de SE que realicen razonamiento en presencia de incertidumbre; y un largo etcétera. Un dato también significativo, que refleja los avances experimentados en las técnicas de representación, es que la mayoría de los sistemas expertos construidos hasta mediados de los años 80 realizaban tareas de diagnóstico; por tanto, de análisis. A partir de entonces se abordaron igualmente tareas de diseño, que generalmente, por ser una labor de síntesis, necesitan considerar mayores volúmenes de conocimiento.
Pero en esta época avanzaron otras muchas ramas de la IA, no solo los SBC. Uno de los problemas que tuvieron mayor atención siguió siendo el del procesamiento del lenguaje natural (PLN). Las investigaciones realizadas se dividieron en: métodos para hacer computables los modelos cognitivos utilizados por los humanos, denominado PLN General; y procedimientos efectivos para entablar procesos de comunicación entre el hombre y la máquina -sin considerar su plausibilidad psicológica-, denominado PLN Aplicado. Además de la equiparación de patrones y el análisis sintáctico, surgen los métodos basados en la utilización de gramáticas semánticas; aplicados en los sistemas: LIFER y SOPHIE. En este enfoque las categorías gramaticales son sintácticas y semánticas. Existe también la posibilidad de combinar las ventajas de las gramáticas semánticas, las transformaciones sintácticas, y la equiparación de patrones en un mismo sistema. Este esquema, denominado multiestratégico, se ha implementado en el sistema DYPAR.
A finales de los años ochenta se divulgó el uso de los interfaces de lenguaje natural, fundamentalmente para el acceso a grandes bases de datos, aunque también se han utilizado como intérprete de comandos, y en la consulta y ejecución de sistemas expertos sencillos. Estos sistemas tratan de solventar las diferencias que existen entre los dos tipos de lenguajes -el lenguaje natural y el propio de la base de datos (p.ej., SQL)- y de esta manera ofrecer al usuario una herramienta mucho más sencilla y flexible. Se trata de un tipo de interfaz que pretende que el lenguaje de comunicación con la máquina no sea ni tan estricto como los lenguajes artificiales, ni tan ambiguo como los lenguajes naturales. Estas aplicaciones son factibles porque no se trata de crear un intérprete universal del lenguaje humano, sino uno restringido a las expresiones más frecuentes en un dominio concreto; por lo tanto, cada uno de estos interfaces depende de la información contenida en la base de datos que corresponda. Uno de los más conocidos, DYPAR, se divide funcionalmente en dos partes: la primera se encarga de leer y compilar las gramáticas y la segunda utiliza esa gramática para entender las frases de los usuarios y ejecutar las acciones asociadas con cada una de estas frases. DYPAR permite construir gramáticas semánticas, en las que la sintaxis del lenguaje está implícita en los patrones semánticos. El fundamento de su funcionamiento es la equiparación de patrones, en concreto, la comparación de la frase de entrada con los patrones contenidos en las reglas de la gramática.
Otra aportación indudable en la CLN fue la instanciación de marcos de casos. Su origen se remonta a la propuesta del lingüista Fillmore. Esta metodología es una de las principales técnicas de análisis que se sigue aplicando en la actualidad. Su utilidad descansa en la utilización de un proceso de naturaleza recursiva y en la capacidad de combinar reconocimiento ascendente a partir de los elementos clave de la sentencia y descendente del resto de componentes menos estructurados. La clave del reconocimiento es semántica: un mismo caso engloba diferentes estructuras sintácticas con un mismo significado. Para llevar a cabo esta correspondencia se parte de una representación canónica del significado mediante los Grafos de Dependencia Conceptual (un tipo de red asociativa). El proceso consiste sencillamente en buscar los marcos adecuados para interpretar la frase que se está analizando, y para ello se utiliza primero la búsqueda de los marcos a partir de una serie de palabras clave que los identifican; siendo éstas verbos que corresponden con diferentes acciones primitivas (p.ej. "comprar" supone realizar una transferencia de la relación abstracta de posesión, denominada en el modelo *ATRANS*, que tiene un tipo de marco determinado con campos como: objeto, agente, receptor, etc., que permiten identificar los elementos significativos del enunciado en cuestión). Una vez identificado el caso se intentan completar su estructura con los elementos de la frase.
En el campo de la CLN, debe recibir una mención especial el sistema XCALIBUR, cuyo objetivo era proporcionar diálogo en lenguaje natural con el sistema experto XSEL: un asistente de venta de Digital, cuya misión era aconsejar y seleccionar los componentes apropiados que debían formar parte de la configuración de un computador VAX, que finalmente generaba el sistema experto R1. El interfaz de lenguaje natural recibía frases como: ¿Cuál es el disco duro 11780 más grande por debajo de $40,000?, y respondía con sentencias del tipo: El rp07aa es un disco duro de 516MB que cuesta $38,000. Hay que recordar que este sistema se ha utilizado en condiciones reales con un indudable éxito.
Dentro del campo de la traducción automática, después de un período de relativo abandono debido al informe ALPAC, se produjo un nuevo impulso tanto en Europa como en Japón. Podemos destacar el proyecto Eurotra (comenzó en 1978), patrocinado por la Comunidad Europea, cuyo principal objetivo es proporcionar herramientas que faciliten y automaticen, en la medida de lo posible, las tareas de traducción inherentes a dicha organización. En la actualidad, este proyecto emplea a 160 investigadores de diferentes grupos nacionales. Japón, por su parte, viene desarrollando desde 1980 un esfuerzo considerable en el tema, como queda reflejado en el proyecto de la Universidad de Kyoto, financiado por el ministerio de industria. Uno de los principales problemas a los que se enfrentan estas investigaciones es el tratamiento de la ambigüedad del lenguaje. La principal conclusión de las técnicas aplicadas es la necesidad de utilizar información contextual del dominio para afrontar dicho problema. En los casos en que el conocimiento aplicado sea insuficiente, se establece una etapa denominada de "postedición", en la que se tiene opción de ajustar los resultados obtenidos.
En lo que se refiere al reconocimiento de imágenes, se amplían y matizan las fases del proceso propuestas en la primera etapa. El fundamento común de todos los modelos consiste en introducir conocimiento del dominio en la fase de segmentación de las imágenes de tal forma que se focalice la búsqueda de las características más relevantes en un contexto dado. Así, el sistema IGS (interpretation-guided segmentation) probó que, en la práctica, cuanto más conocimiento sea tenido en cuenta (proporcionado por el propio sistema o por el usuario), más eficiente y eficaz será el proceso realizado. Por otro lado, se crea el concepto de "ciclo de la percepción", para expresar las fases que atraviesa un proceso de interpretación guiado por el conocimiento aplicable. Otra aportación importante sobre dicho ciclo consistió en distinguir lo que se denomina "imagen del dominio", que se refiere a la imagen real en tres dimensiones, de la "imagen de la escena", que determina su visión en dos dimensiones. El objetivo de un sistema de visión es encontrar la descripción más específica y detallada, entre las que el sistema tenga disponibles, de la imagen objeto. Para ello se realiza un complejo proceso de búsqueda y refinamiento de las hipótesis utilizadas en la interpretación de la imagen. En lo que se refiere a los formalismos de representación utilizados, aunque se han construido aplicaciones con reglas, redes semánticas y heurísticas, los más adecuados han sido los marcos (dos ejemplos representativos son: SIGMA y ALVEN).
En lo que se refiere al aprendizaje, esta etapa supone, por fin, el desarrollo y la divulgación de las principales técnicas efectivas del campo. Dentro de la imperante formulación simbólica del problema, se asume, al igual que en el resto de las áreas, la necesidad del conocimiento del dominio. Es también la época en la que aparecen las primeras aplicaciones reales y se establecen los ciclos de conferencias a nivel mundial sobre este tema (la primera celebrada en la Universidad de Carnegie Mellon en 1980). En 1983, Carbonell, Michalski y Mitchell realizaron un análisis metodológico muy clarificador sobre el estado del arte. Los primeros esfuerzos con relativo éxito siguieron teniendo lugar dentro del aprendizaje inductivo, en concreto, dentro del campo del aprendizaje basado en ejemplos. Las técnicas de aprendizaje inductivo se aplicaron fundamentalmente para resolver la tarea de clasificación. Generalmente estas formulaciones parten de una clasificación de las observaciones procesadas de acuerdo con alguna fuente externa (llamada «oráculo»), siendo su objetivo predecir la clasificación correcta de instancias todavía no presentadas en base a la búsqueda de semejanzas en las clasificaciones observadas (por esto se le conoce como aprendizaje basado en la semejanza, SBL: similarity based learning). Una opción muy extendida para llevar a cabo la clasificación es la utilización de árboles de decisión como estructura de representación básica que establece la buscada correspondencia entre el espacio de entradas y de salidas. Si analizamos estos sistemas en el nivel de esta tarea, la clasificación, podemos afirmar que este tipo de aprendizaje produce una corrección del conocimiento del dominio. Un salto cualitativo dentro del razonamiento inductivo está asociado a los métodos que carecen de una fuente explícita de clasificación de ejemplos. En estos casos el problema se centra en agrupar convenientemente los objetos y establecer una descripción de dichos grupos. Surge aquí el problema adicional de establecer las bias adecuadas para generar conjuntos lo más útiles posibles -normalmente aquellos cuya facultad de predecir los atributos relevantes que los describen sea mayor-. Aparece por lo tanto el problema de manipular descripciones probabilísticas de conceptos. Otro ejemplo del enfoque inductivo son los sistemas de descubrimiento. Su objetivo -inicialmente demasiado elevado- era realizar descubrimientos de carácter científico, igual que lo hacen los humanos. Su realización práctica ha logrado establecer heurísticas que permiten obtener leyes científicas válidas en el contexto seleccionado (p.ej., BACON). Todos estos paradigmas, al ser de naturaleza inductiva, tienen como rasgo común la no monotonocidad del conocimiento aprendido: la posibilidad de que el nuevo conocimiento inferido desmienta las hipótesis previas.
Como resultado de la dependencia del número y el tipo de ejemplos disponibles en la formulación inductiva del aprendizaje, y como expresión de la emergente tecnología relativa al desarrollo de sistemas expertos, surgió a lo largo de los años 80 un enfoque más centrado en la formulación adecuada del conocimiento disponible que en la búsqueda de mecanismos genéricos de generalización inductiva. Surgen entonces las que se denominaron aproximaciones basadas en el conocimiento intensivo; o métodos de compilación del conocimiento, ya que se aplicaron como una herramienta para hacer más operacional el conocimiento de una tarea, cuya definición inicial era demasiado abstracta como para resolver adecuadamente el problema. En realidad son estrategias de aprendizaje analítico, ya que se basan en el análisis del conocimiento disponible; tienen, por tanto, naturaleza deductiva; y cumplen la condición básica de este paradigma: la monotonocidad del conocimiento aprendido. El objetivo deja de ser realizar una tarea más correctamente y se transforma en mejorar la eficiencia con la que se ejecuta. El mecanismo de aprendizaje de estos métodos se basa en resumir en una sola regla el árbol de explicación o prueba de un ejemplo con una teoría. Por esto son también llamados métodos basados en la explicación (explanation based learning, EBL). La gran ventaja es que pueden aprender conocimiento útil a partir de un único o un conjunto reducido de ejemplos (p.ej., múltiple EBL). La principal desventaja son sus exigencias con respecto a la formulación de la teoría del dominio, se requiere que sea completa, consistente, y tratable (evaluable con unos recursos razonables) (p.ej., las reglas básicas del juego del ajedrez definen una teoría de estas características, pero el rango de decisiones es inabordable: 10120). Estas técnicas analíticas se pueden aplicar en multitud de tareas, en tanto en cuanto la teoría puede describir conocimiento de control, de percepción, de planificación, etc. Destaca su utilización en el paradigma denominado resolución de problemas (problem solving). En este caso se aprenden heurísticas basadas en el conocimiento del dominio que determinan qué estado o qué operador debe elegirse en un momento dado. Con este mismo objetivo, pero con un planteamiento diferente, inspirado en el campo de psicología cognitiva, encontramos un modelo que aprende heurísticas de control cuando las ya existentes no son capaces de resolver una determinada situación. El mecanismo de generalización se denomina chunking, algo así como encapsulamiento; ya que, al igual que el resto de los métodos analíticos, realiza una compresión del proceso de búsqueda realizado, que en este caso sirve para salvar un punto de indecisión.
Como una prolongación del planteamiento general de los problemas de búsqueda de la etapa anterior y dentro del planteamiento analítico y deductivo del aprendizaje, debemos mencionar el aprendizaje de macro-operadores. Aunque en otro contexto, sigue siendo un aprendizaje basado en una explicación, que en este caso no está formada por reglas que describen el conocimiento del dominio, sino por operadores aplicados a lo largo de un proceso de búsqueda de la solución. De igual forma que en EBL, el conocimiento aprendido es una regla que resume el proceso realizado: el camino que conduce desde un determinado estado hasta un estado meta. La nueva regla obtenida que produce el mismo efecto que una secuencia de operadores se denomina macrooperador, y reúne en su parte antecedente todas las características del problema inicial que se necesitan para dicha solución, así como todas las acciones que no se han deshecho por la aplicación de los diferentes operadores durante el camino encontrado. Este método se ha aplicado principalmente en la planificación de la tarea de un robot.
Una tercera aproximación al problema del aprendizaje, que no puede clasificarse como puramente deductiva ni inductiva, proviene fundamentalmente de estudios sobre la plausibilidad psicológica más que sobre la realización práctica. La dificultad intrínseca de una formulación correcta y completa de la teoría del dominio asociada a los métodos basados en la explicación (EBM), junto con la constatación de los mecanismos de razonamiento analógico en el ser humano, dio lugar al desarrollo del aprendizaje por analogía. Este tipo de realizaciones exige tener mecanismos de almacenamiento y acceso a datos muy eficientes, dado el volumen creciente de información manipulada. Para llevar a cabo estos sistemas se han conjugado mecanismos potentes de organización dinámica de memoria, de indexación de estructuras, de búsqueda de correspondencias entre situaciones semejantes y de generalización. En estos procesos se realiza una generalización inductiva sobre las relaciones (determinaciones que se cumplen en un determinado dominio (el «origen»), suponiendo que también se cumplen en otro dominio (el «destino») relacionado con aquél.
Después de los períodos de iniciación (secciones 1.2.1 y 1.2.2), y del de divulgación y diversificación de las técnicas básicas aplicadas en diferentes dominios y tareas (sec. 1.2.3), comenzó a finales de los años 80 una época de asentamiento y revisión de resultados caracterizada por un cambio de conceptualización del conocimiento y por una preocupación por los aspectos metodológicos en los diferentes campos (SBC, aprendizaje, visión, CLN, etc.). En cuanto al modelo del conocimiento adoptado ¾ tal y como analizaremos a continuación¾ se observa un predominio de los esquemas distribuidos con una capacidad intrínseca de aprendizaje frente a la parcelación, concentración y separación de las tareas de aprendizaje que caracterizaba la etapa anterior. Estos cambios se producen tanto en el campo simbólico (p.ej., razonamiento basado en casos) como en el subsimbólico (p.ej. redes conexionistas multicapa).
Las técnicas de representación más extendidas de la época anterior (sec. 1.2.3) en el desarrollo de los sistemas expertos (reglas, marcos o en una combinación de ambos) adolecían de una serie de desventajas que terminaron minando las sobrealimentadas expectativas puestas en ellos ¾ animadas muchas veces por meros intereses económicos¾ . Uno de los principales problemas de estos sistemas era su relativa fragilidad: a la vez que pretendían emular el comportamiento de un experto, tenían verdaderas dificultades para enfrentarse a un problema imprevisto. Para paliar esta limitación se intentaron aplicar técnicas de aprendizaje (p.ej., inducción de nuevas reglas a partir de ejemplos en Meta-Dendral [Lindsay et al., 80], descubrimiento de nuevas asociaciones entre pacientes en RX [Blum, 82], descubrimiento de nuevos conceptos y relaciones [Lenat, 82], aprendizaje de modelos de adquisición de reglas en TEIRESIAS [Buchanan & Shortliffe, 84], etc.), pero resultaron ser demasiado dependientes de la tarea y el dominio en concreto. Además, se detectaron diversos problemas en cada una de las fases en las que se puede dividir su realización: adquisición del conocimiento, desarrollo, y mantenimiento.
Una de las deficiencias más detectada era la falta de metodología, o si se prefiere, de ingeniería. Prácticamente, las únicas técnicas aplicadas eran el prototipado y el análisis de protocolos. La fase de adquisición del conocimiento es la que más esfuerzo y tiempo requiere. Para su realización se concertaban una serie de entrevistas con el experto, que se desarrollaban de acuerdo con una estructura muy pobre (análisis de protocolos), y cuyo propósito era extraer todo el conocimiento relevante para llevar a cabo la tarea encomendada. Este proceso era largo y costoso, ya que los humanos son poco aptos para describir su conocimiento mediante reglas. Por otro lado, se partía del presupuesto de que una modelización excesiva desde el principio suponía muchas veces un esfuerzo inútil, dado que la configuración del sistema se iba perfilando según avanzara el proceso de entrevistas sucesivas, siendo muchas veces necesario replantear el esquema inicial (prototipado). El modelo interno del sistema, su arquitectura, se ajustaba tanto al que se suponía que era el modelo del experto: un conjunto de fragmentos independientes de conocimiento que había que descifrar, que se trivializaba el proceso de abstracción y estructuración propio de cualquier otro producto de la ingeniería del software. Conviene recordar que el objetivo primordial de dicha ingeniería es que el diseñador del programa no tenga que construir todo un programa completo, sino sólo ciertas partes del mismo, y más que "construirlo", se intenta que sea suficiente con especificar una descripción que se aplica a un programa ya creado. Se trata, por tanto, de abstraer lo que el programa debe hacer, de tal forma que pueda ser reutilizado y corregido fácilmente, siendo una cuestión secundaria la sintaxis que permite llevarlo a cabo. Sin embargo, en los SBC el problema consistía en pasar de la descripción del conocimiento en lenguaje natural, a una estructura de representación concreta ¾ generalmente reglas o marcos¾ ; el salto entre ambas, desde luego, era muy considerable.
¿Qué pasa con todos aquellos problemas que comparten una cierta estructura?. Un intento de aprovechar en los SBC dicha circunstancia fueron los llamados sistemas "concha" (shell), que pretendían aportar la estructura de inferencia requerida para solucionar un determinado tipo de problemas. De tal forma, que para cada caso concreto bastara con actualizar el conocimiento del dominio. Sin embargo, los mecanismos de inferencia utilizados: encadenamiento hacia adelante, hacia atrás o combinado, eran una aproximación demasiado gruesa en relación a la estructura de las tareas que se querían resolver: planificación, control, diagnóstico, clasificación, etc. La suposición inherente a todos estos planteamientos era que se podía separar el conocimiento de su uso en inferencia. Recordemos que esta práctica tiene su origen (sec. 1.2.3) en el sistema EMYCIN, que resultó de vaciar MYCIN de reglas de enfermedades infecciosas, dejando las estrategias de razonamiento y las facilidades de explicación.
Por otro lado, en lo que se refiere al planteamiento metodológico de las problemas, hoy en día prevalece la postura de que para describir en abstracto los problemas es necesario modelar claramente el conocimiento, de tal forma que se puedan identificar la tarea y el método para resolverlos. Por ejemplo, la tarea de clasificación puede definirse como: "la búsqueda de una relación de correspondencia entre las observaciones y las clases a través de un conjunto de reglas de inferencia". Lo que caracteriza la clasificación frente a otras tareas es que las clases deben ser previamente conocidas, pertenecientes a un conjunto, no son el resultado de un proceso de construcción (si fuera un proceso constructivo cualquier solución de cualquier problema sería un proceso de clasificación, ya que a cada "entrada" le corresponde una "salida"). La tarea de clasificación puede descomponerse en una sucesión de subtareas. Por ejemplo, en el caso concreto de la clasificación heurística la inferencia se realiza en tres etapas: abstracción, equiparación heurística y refinamiento [Clancey, 85]. A su vez, estas subtareas pueden modelarse en base a otras tareas más simples: la abstracción como un proceso de búsqueda dirigido por los datos; la equiparación heurística como una búsqueda dirigida por las hipótesis; y el refinamiento como una combinación de los dos procesos de búsqueda anteriores. Esta técnica de modelar el conocimiento nos permite aislar el objetivo: la tarea que quiere realizarse, la clasificación, del método con el que se resuelve, heurístico. Siendo el método el que determina la descomposición correspondiente. En realidad se busca un nuevo nivel de abstracción que permita combinar métodos y tareas en función de los objetivos. Los elementos que definen este nivel se denominan tareas genéricas [Chandrasekaran et al., 92]. Apoyándose en estas ideas se ha desarrollado una metodología de construcción de SBC orientada a modelos conocida como KADS (Knowledge-Based Systems Analysis and Design) [Wielinga et al., 92]. En pocas palabras, esta metodología estructura las fases, etapas, actividades y resultados que deben seguirse para obtener una descripción del sistema mediante modelos que deben representar conceptos relevantes, diseñados para proporcionar el comportamiento deseado en el dominio. Algunas de las ventajas que se buscan con esta metodología son: estructurar y sistematizar el desarrollo de los SBC, distinguir las actividades técnicas de las de gestión, facilitar el mantenimiento y las ampliaciones, proporcionar un estándar de desarrollo similar al de otros campos de la ingeniería del software, soportar la adquisición del conocimiento y generar una librería de modelos reutilizables. Actualmente, CommonKADS es el estándar europeo para el desarrollo de sistemas basados en el conocimiento. Esta metodología es el resultado del proyecto ESPRIT KADS-II (P5248) que es una continuación del proyecto KADS. Cubre todos los aspectos del desarrollo de un SBC (conocimiento estratégico, gestión del proyecto, integración, adquisición del conocimiento y desarrollo del producto) enmarcados en un único ciclo de vida de carácter espiral, que llega incluso a la definición del programa que finalmente será ejecutado ùKADS-I (ESPRIT-I P1098) se quedaba en la definición del modelo conceptualù [Van de Velde et al., 94]. Una de las principales contribuciones de este proyecto es el introducir las últimas técnicas aplicadas en la ingeniería del software en el campo de la IA.
La propia designación de "sistemas expertos" ha llegado a tener, muchas veces injustamente, connotaciones negativas ¾ alguna vez hemos oído la expresión YAES ("yet another expert system")¾ . No es nuestro objetivo realizar un análisis profundo sobre este fenómeno, ya hemos señalado que el modelo adoptado, la falta de metodología y las esperanzas puestas en la tecnología entonces aplicada, junto con el elevado coste de su desarrollo y mantenimiento, ha producido un cierto rechazo sobre el tema. En realidad, el objetivo en sí: intentar que un producto de software se comporte de modo parejo a como lo haría un experto en un área muy concreta, sigue siendo una meta que no debe despreciarse. De hecho, sería una grave falta de juicio no reconocer los éxitos que estos sistemas han tenido (véanse las numerosas aplicaciones citadas en la sección 1.2.3). En este sentido, queremos mencionar algunas de las aplicaciones que han desarrollado personas cercanas a nuestro grupo de trabajo: CAEMF [Marín, 86] (dedicado al diagnóstico y seguimiento anteparto del estado materno-fetal), SUTIL [Barro, 87] (aborda el problema de la monitorización inteligente en una unidad de cuidados coronarios y resuelve algunos problemas importantes relacionados con los sistemas expertos en tiempo real), MEEDTOL [Otero & Mira, 88; Otero, 91] (es una herramienta para el desarrollo de sistemas expertos que incluye un procedimiento propio para la representación del conocimiento mediante "magnitudes generalizadas", una especie de micromarcos), TAO [Mira et al., 87; 91] (consejero de terapia oncológica que incorpora el conocimiento estratégico necesario para la inclusión de enfermos en protocolos de quimioterapia y para el seguimiento del efecto del protocolo), TAO-MEEDTOOL [Barreiro, 91] y DIAVAL [Díez, 94] (sistema experto para ecocardiografía basado en redes bayesianas).
Actualmente, parece haber consenso en superar las limitaciones de las técnicas aplicadas en épocas pasadas. Uno de los paradigmas más aceptados y utilizados es el del razonamiento basado en casos. Presentamos a continuación las manifestaciones de un investigador de reconocido prestigio que señala:
Uno de los ejemplos aducidos por Schank es el de los estudiantes de medicina en los Estados Unidos. Durante los dos primeros años éstos se dedican, casi exclusivamente, a aprender el contenido de los libros sobre el tema con vistas a superar un test; sin embargo, "nadie querría ser operado por un estudiante de segundo curso, con independencia de la calificación obtenida en dicha prueba". Realmente, el mundo es muy complejo como para ser reducido a las reglas que forman las teorías que construimos. Las generalizaciones que realizamos son constantemente modificadas para acomodarse a las sorpresas que nos depara la realidad circundante. "Tener un amplio, y convenientemente indexado conjunto de casos, es lo que diferencia al experto del estudiante primerizo formado a partir del conocimiento reflejado en los libros". Roger Schank pertenece a una corriente de opinión dominante, que confía en que el Razonamiento Basado en Casos (RBC) es un modelo adecuado para la resolución de problemas, lo cual implica una concepción bastante alejada de la mayoría de los sistemas de IA construidos hasta ahora.
Los fundamentos en los que se apoya el RBC tienen su origen en los modelos de representación conceptual del campo de la psicología cognitiva [Schank, 80] y en el razonamiento analógico aplicado a dominios de conocimiento restringido [Carbonell, 86]. El objetivo consiste en conjugar de forma efectiva el razonamiento causal con técnicas de almacenamiento y agrupación eficiente de sucesos en memoria. Desde el punto de vista estructural, el elemento básico de representación en este paradigma son los MOPs (Memory Organization Packets) [Schank, 82]: unidades primarias de almacenamiento de una memoria dinámica que sirven para identificar las partes comunes observadas en las experiencias de diferentes episodios. A diferencia de los guiones (secuencia estereotipada de acciones almacenada en una sola estructura en la memoria), los MOPS reúnen, mediante enlaces creados dinámicamente, las escenas y los diferentes elementos de conocimiento que son relevantes para interpretar una determinada situación. Estos enlaces cambian continuamente, en función del descubrimiento de nuevas semejanzas o diferencias que se consideran más relevantes para la tarea en cuestión.
Los casos se organizan en una red en la que existen enlaces de abstracción y especialización, formando una jerarquía de abstracciones. Estos enlaces juegan un papel esencial ya que determinan qué información y cuándo está disponible. Los casos están formados por conocimientos acerca de las experiencias con las que nos enfrentamos. El RBC tiene como proceso básico de actuación la capacidad de recordar. Consiste esencialmente en utilizar el conocimiento disponible que tenga una mayor relación con el problema planteado. Aunque en este modelo no se parta de hechos de una teoría más o menos formalizada (como en el caso de los SBR), se accede a situaciones previas para guiar el proceso de búsqueda de la solución de los problemas nuevos planteados [Hammond, 86]. La red de casos representa el conocimiento del dominio. La idea clave que utiliza su esquema de funcionamiento se apoya en que cuando escuchamos un relato, intentamos entenderlo etiquetándolo en nuestra memoria [Schank, 82]. Cuantos más detalles contenga el relato más fácil será recordarlo, ya que podrá ser accedido a través de un mayor número de etiquetas. Los casos pueden ser: planes (DAEDALUS [Allen & Langley, 90]), diagnósticos (CASEY [Koton, 88]), diseños (CYCLOPS [Navinchandra, 91]), recetas culinarias (CHEF [Hammond, 86]), disputas laborales (PERSUADER [Sycara, 87]), menús (JULIA [Hinrichs, 92]), disputas legales sobre patentes (HYPO [Ashley, 90]), soluciones de problemas construidas por analogía (PRODIGY [Veloso & Carbonell, 94]), etc.
El razonador basado en casos resuelve nuevos problemas adaptando los casos relevantes de su biblioteca. En concreto, un sistema de este tipo debe: extraer de los datos de entrada las características que mejor puedan utilizarse para indexar la memoria de casos; recuperar los casos relevantes basándose en la semejanza con la entrada; seleccionar el mejor caso(s); adaptar los caso(s) para que cumplan las especificaciones del problema; evaluar la solución con vistas a determinar si debe ser reparada o si puede ser directamente incorporada a la memoria de casos; en el caso de que hubiera habido reparación, recordarla indexándola convenientemente; y, finalmente; realizar las generalizaciones pertinentes en función de los nuevos casos disponibles.
Un aspecto esencial del RBC es que su esquema de funcionamiento básico incorpora la capacidad de aprender. Es por ello que también se ha considerado tradicionalmente como un subcampo del aprendizaje. Abarca diversos tipos de aprendizaje: aprender nuevos casos que ayuden a resolver problemas [Veloso & Carbonell, 94], aprender características que predigan problemas [Hammond, 89], aprender reparaciones aplicables en diversas situaciones [Sycara, 87], aprender nuevos índices [Sycara & Navinchandra, 89], y ampliar la jerarquía de casos describibles [Vilain et al., 90]. Para ello, se atiende a la explicación de las causas que determinaron las decisiones tomadas ¾ accesibles a través de un modelo causal creado al efecto [Sycara, 87]¾ ; por ejemplo, aplicando algún método analítico de aprendizaje (del tipo EBL, véase la sección anterior). Por tanto, estos sistemas pueden explicar el aprendizaje realizado en términos semánticos, relativos a los objetos del dominio.
Para comentar la importancia que últimamente se le está dando a otro de los formalismos de representación en boga, resumiremos algunas ideas escritas por Leslie Helm en el periódico Los Angeles Times en su edición del 28 de octubre de 1996 (home edition). Según la columnista:
Una vez más, basándonos en el espíritu de este artículo, podemos predecir un nuevo descrédito ¾ si así se quiere interpretar¾ de esta nueva tecnología. Como muchos investigadores defienden, es muy improbable que un sólo formalismo sea la solución de muchos problemas. Además, debemos recordar que estas redes necesitan gran cantidad de probabilidades numéricas, y normalmente no se dispone de toda esta información mediante estudios objetivos, por lo que se recurre a estimaciones subjetivas de expertos humanos. No obstante, los avances en este campo (cuyo resurgir se debe fundamentalmente a la introducción de la propiedad de separación direccional en el modelo) están demostrando tener un campo de aplicación muy prometedor (podemos destacar un sistema bayesiano para el diagnóstico de valvulopatías, desarrollado por un miembro de nuestro departamento [Díez, 94]). Actualmente, además del interés comercial, existen ciclos de conferencias y numerosas publicaciones que reflejan la importancia científica de este "renacimiento".
Otro elemento que caracteriza la situación actual es el resurgimiento del interés en los llamados modelos conexionistas (llamados así por estar formados por una red de unidades altamente interconectadas), también conocidos como redes neuronales (sec. 1.2.1). Junto al declive del modelo de computación aplicado en los sistemas expertos y a las razones que siempre han motivado el interés por este modelo de computación: la constatación de la versatilidad del modelo neuronal en tareas como: percepción, reconocimiento de caracteres, memoria asociativa, aproximación de funciones lineales, predicción de series temporales, optimización, control adaptativo y aprendizaje; se produce a mediados de los años 80 ¾ después de un largo período de relativa inactividad (sec. 1.2.1)¾ una nueva propuesta [Rumelhart et al., 86] que permite superar las restricciones de los modelos previos. Esta nueva aportación mantiene el concepto de red como una arquitectura modular repartida en un elevado número de elementos que realizan una función analógica no lineal y que están conectados entre sí según lo disponga la configuración elegida. La gran diferencia del algoritmo utilizado, backpropagation, estriba en que la función umbral se sustituye por una función derivable (una sigmoide) que permita la retropropagación de la función de error que guía el aprendizaje supervisado por el método del gradiente. En este tipo de aprendizaje, la relevancia encontrada en las observaciones presentadas se fundamenta ¾ implícitamente¾ en un análisis estadístico. Al fin y al cabo, una red actúa como un clasificador con capacidad de predicción. Por lo tanto, al igual que en los métodos SBL (sec. 1.2.3), se requiere un número elevado de ejemplos para llegar a un punto de convergencia en el modelo. Otras razones que también avalan el interés por las redes neuronales son: la tolerancia a fallos, la inherente velocidad computacional, el paralelismo y la posibilidad de realizar directamente su implementación hardware. Este tipo de computación pretende convertirse en una tecnología complementaria de la IA simbólica para aquellos problemas que tengan que ver con medios cambiantes y parcialmente conocidos que aconsejen soluciones paralelas y en tiempo real, que sean capaces de afrontar la variabilidad del medio.
El gran problema que debe afrontar el modelo conexionista, tal y como se planteó en su día en la formulación simbólica, es la manipulación del conocimiento y de la inferencia en la red. El conocimiento explícito de la red se manifiesta en los pesos de las conexiones y en la configuración de los enlaces entre las distintas unidades. El conocimiento implícito proviene de los distintos tipos de neuronas, determinados por las clases de funciones de computación local aplicada sobre las entradas (p.ej., en el caso del backpropagation, la efectividad de la red viene determinada por la manipulación de una serie de parámetros como son el ratio de aprendizaje y el momentum). La configuración multicapa generalmente elegida es la de una red con unidades dispuestas en tres grupos diferenciados o capas. Las unidades de entrada reflejan la codificación de los patrones asociados a los ejemplos presentados, las unidades intermedias (también llamadas unidades ocultas) constituyen la estructura interna de la red, y las unidades de salida representan las clases a las que pertenecen los ejemplos presentados.
La aplicación práctica de estos modelos refleja la importancia que tiene la determinación del conocimiento inicial para lograr unos resultados satisfactorios. Algunas de las aplicaciones más conocidas son: el programa NETtalk [Sejnowski & Rosenberg, 87] (fue una de las primeras demostraciones sobre la utilidad de las redes neuronales; los resultados fueron limitados, pero sentó las bases del campo), aprende a pronunciar texto escrito; reconocimiento de caracteres escritos [Le Cun et al., 89] (se utilizaba para leer las direcciones y apartados de las cartas de correo; con sus tres capas ocultas de 768, 192, y 30 unidades respectivamente, es una de las aplicaciones más toscas hasta la fecha); ALVINN (Autonomous Land Vehicle In a Neural Network) [Pomerleau, 93] (aprende a dirigir a un vehículo siguiendo una línea de un carril en una autopista imitando el comportamiento del conductor a partir de pares imagen/dirección; es sorprendente comprobar que el sistema ha permitido alcanzar velocidades de 130 Km/h en autopistas cercanas a Pittsburgh).
Los resultados obtenidos (p.ej., [Mooney et al., 89]) indican que el aprendizaje en las redes es largo, y aunque la clasificación generada de los ejemplos presentados sea ligeramente mejor que en el enfoque simbólico, éstos requieren de 100 a 1000 veces más de tiempo de entrenamiento. Dos de los principales inconvenientes de las formulaciones conexionistas son: la necesidad de realizar una codificación arbitraria de las entradas y las salidas, y la inaccesibilidad al conocimiento distribuido implícito en la red (sólo se accede a la respuesta de la red). Sin embargo, ya hemos comentado la utilidad práctica de este planteamiento. Luego el problema no es cuál es mejor formulación, si la simbólica o la conexionista; la cuestión es saber cuándo debe aplicarse una u otra, o la combinación de ambas. Por ejemplo, en el caso ya comentado del sistema ALVINN, el programa sólo era capaz de seguir una línea y no podía circular en situaciones reales con tráfico. Actualmente se pretende combinar las capacidades primarias del sistema con conocimiento simbólico de más alto nivel con el fin de afrontar situaciones más reales. Esta es una constante en este tipo de aplicaciones. Los sistemas híbridos son frecuentes cuando la IA se aplica a situaciones palpables en el mundo real.
El enfoque conexionista ha estado tradicionalmente separado del planteamiento simbólico. Sin embargo, últimamente se están realizando un gran número de aplicaciones tendentes a aprovechar las ventajas respectivas de ambos tipos de formulaciones (algunos ejemplos representativos son: [Shavlik & Towell, 89; Towell et al., 90; Romaniuk & Hall, 91; Thrun & Mitchell, 1993; Towell & Shavlik, 94]). Uno de los temas que reciben un mayor interés es la extracción de las reglas que reflejan el conocimiento contenido en una red conexionista [Omlin & Giles, 95] (existe un ciclo de conferencias y una lista de correo electrónico sobre este tema). Estas formulaciones mixtas de aprendizaje ¾ como la señalada simbólico-conexionista¾ se conoce más genéricamente como estrategias híbridas. Bajo este nombre se engloban también el resto de los modelos simbólico-subsimbólicos, como puedan ser los simbólico-numéricos [Zahng, 94] y los simbólico-genéticas [Vafaie & De Jong, 94]. Básicamente, lo que hacen estos métodos es utilizar el conocimiento del dominio y un conjunto de ejemplos para desarrollar un modelo que permita clasificar bien futuros ejemplos. La clave del asunto está en aprovechar la información de cada una de las dos fuentes para que ambas se complementen entre sí.
En esta revisión que estamos realizando sobre la situación actual, queda patente la incorporación de la capacidad de aprender en las distintas formulaciones. Esto es una consecuencia clara de la paulatina maduración del campo. Al fin y al cabo, el aprendizaje es una de las cualidades más definitorias de la inteligencia, además de una exigencia deseable en cualquier sistema que pretenda llevar el distintivo de IA. Precisamente, en lo que se refiere a la tendencia actual de las investigaciones sobre las técnicas de aprendizaje, se observa, al igual que se ha comentado sobre los SBC, un intento de avance en los aspectos metodológicos, a la par que una preferencia por las formulaciones mixtas ¾ ya introducidas¾ . Uno de los avances más significativos se produjo cuando se realizaron los primeros estudios sobre el significado de las transformaciones realizadas en estos sistemas. Nos referimos al análisis sobre las denominadas bias: son el conjunto de todos los factores internos (p.ej., un agente en interacción con el medio), generalmente ocultos a nivel consciente, que influyen en la selección/interpretación/modelización/etc. de aquello (realizada por dicho agente) que determina el comportamiento del sistema de aprendizaje [Mitchell, 80; Michalski, 83; Utgoff, 84, 86; Rendell, 89; Subramanian, 89]. El acceder a la descripción del principio que guía el proceso de aprendizaje abrió las puertas a la interacción entre modelos que inicialmente se consideraban de forma aislada: deductivos, inductivos, analógicos, abductivos; y, más adelante, también conexionistas y bayesianos. Hoy en día, después de un periodo en el que se establecieron las bases que permitían llevar a cabo estas formulaciones de carácter mixto [Cohen, 90; Falkenhainer, 90; Russell & Grosof, 90], se ha producido una auténtica eclosión de modelos y aplicaciones [Lebowitz, 90; Qian & Irani, 91; Cox & Ram, 92; Tecuci, 93; Veloso & Carbonell, 94] como lo demuestra el último número de la colección de libros sobre aprendizaje (el volumen IV de Machine Learning se ha dedicado por entero a ilustrar trabajos en el campo del aprendizaje multiestrategia, incluyendo las concepciones híbridas [Michalski & Tecuci, 94]), además, se han establecido ciclos de conferencias dedicados expresamente al tema. Existen varias formulaciones básicas sobre el tema. Una de las más utilizadas, la deductivo-inductiva, responde a una sugerencia realizada anteriormente [Mitchell, 84], consiste en utilizar el conocimiento expresado en una teoría del dominio incompleta, incorporando a continuación el conocimiento proveniente del trato empírico de ejemplos disponibles, cuyo objetivo es intentar rellenar los vacíos existentes en la descripción inicial de la teoría (algunos ejemplos se pueden encontrar en [VanLehn, 87; Flann & Dietterich, 89; Shavlik & Towell, 89; Hirsh, 90]). Por ejemplo, en el desarrollo presentado en [Hirsh, 90] se aplica EBG (un método analítico de EBL) [Mitchell et al., 86] para obtener generalizaciones válidas a partir de una teoría incompleta del domino, luego se refinan las reglas aprendidas mediante el uso de jerarquías de abstracción de los valores de algunas de las características que se utilizan en la descripción de los objetos del dominio, pero que no estaban directamente disponibles en la teoría aplicada. Cualquier otro modelo multiestrategia que hubiéramos analizado tendría como base una misma concepción del problema, que coincide con el resto de las propuestas de otros campos de la IA en nuestro días, y que consiste en concebir el conocimiento, no como un elemento aislado que depende de una determinada concepción (en este caso: inductiva, deductiva o abductiva), sino como algo que debe ser relacionado y confrontado con otros elementos de conocimiento disponibles, para producir nuevas entidades que superan el cierre léxico de las conectadas. Por lo tanto, también en el campo del aprendizaje se percibe la necesidad de considerar el conocimiento como una red, siendo el principal problema el establecer modelos que incorporen capas en las que formulaciones diferentes puedan interactuar [Boticario & Mira, 96].
Además de estas formulaciones de carácter mixto, existen otros muchos estudios teóricos y desarrollos de aplicaciones del campo del aprendizaje: mejoras y ampliaciones de los algoritmos existentes [Quinlan, 96]; reformulaciones de algoritmos antiguos, como el espacio de versiones [Mitchell et al., 83; Boticario, 88], con el fin de hacerlos más eficientes (formulación en paralelo [Hong & Tseng, 94]), o más versátiles (en un formalismo lógico [Qian & Irani, 91]); arquitecturas integradas que proporcionan un entorno genérico de programación en el cual pueden combinarse procedimientos de búsqueda, inferencia, representación, organización de memoria y aprendizaje (PRODIGY [Carbonell et al., 90], SOAR [Laird & Rosenbloom, 90], THEO [Mitchell et al., 91]à); estudios sobre la complejidad sintáctica y la fiabilidad de los resultados obtenidos ¾ conocido como teoría del aprendizaje computacional ¾ (este campo surgió hace algún tiempo [Valiant, 84; Haussler, 88], hoy en día existe un ciclo de conferencias y un gran interés sobre el tema); sistemas aprendices que se adaptan a las necesidades de cada usuario [Dent et al., 92a, 92b] (es el primer sistema aprendiz utilizado regularmente por un usuario final ¾ en cuyo desarrollo ha tenido la oportunidad de participar el autor del presente proyecto¾ ); aplicación de muchas de las técnicas afianzadas, y consideración de otras alternativas, en nuevos campos de aplicación, como el denominado Descubrimiento del Conocimiento en Bases de Datos (KDD: Knowledge Discovery in Data Bases), cuyo último objetivo ùtodavía lejano [Pérez & Ribeiro, 96]ù sería la creación de un sistema de descubrimiento de conocimiento de propósito general, que engloba, primero, la aplicación de un conjunto amplio de herramientas ùdesde el aprendizaje por descubrimiento, técnicas fuzzi, redes neuronales, métodos estadísticos, etc.ù para extracción de patrones a partir de los datos ¾ conocido como minería de datos (data mining)¾ , y, segundo, la interpretación del conocimiento existente en dichos patrones descubiertos [Fayyad et al., 96] (p.ej., el número 11 del mes de noviembre de 1996 de Communications of the ACM está dedicado por completo a Data Mining and Knowledge Discovery in Databases); ày, un amplio etcétera de otros temas de investigación que podríamos mencionar. Para concluir con este repaso sobre el aprendizaje, queremos resaltar el interés creciente que también existe en este campo por llevar a cabo nuevas propuestas de carácter metodológicos que clarifiquen el campo y abran vías alternativas de investigación [Anderson, 89; Chandrasekaran, 89; Buntine, 90; Clark, 93; Boticario, 94, Boticario & Mira, 94, 96].
Otra de las áreas de mayor actividad sigue siendo el procesamiento del lenguaje natural (PLN). Dentro de este campo, actualmente recibe especial atención la traducción automática. Se puede apreciar un nuevo optimismo en las sucesivas conferencias internacionales sobre el tema (las primeras se celebraron en: Hakone, 1987; Munich, 1989; y Washington, D.C., 1991), debido a: los numerosos grupos de investigación creados (el Centro de Traducción Automática de la Universidad de Carnegie Mellon es uno de los más importantes), el apoyo de las instituciones oficiales (se mantienen los proyectos financiados que surgieron en la época anterior, especialmente en Europa y en Japón ¾ véase la sec. 1.2.3¾ ), las nuevas técnicas desarrolladas en el campo de la lingüística computacional (modelos para el análisis morfológico y sintáctico, y también para la síntesis de los textos de lenguaje natural), la evolución de los interfaces hombre-máquina, y sobre todo, debido a los enormes avances en la tecnología de los computadores (mejoras en la velocidad de proceso, en la arquitectura, en los lenguajes y entornos, etc.). Los estudios realizados consideran que la información del contexto ¾ de la frase en concreto y del texto en general¾ es una fuente esencial para aproximar la traducción correcta entre lenguajes que tienen estructuras gramaticales tan dispares como el japonés y el inglés [Kinsui & Takubo, 90]. En lo que se refiere a los nuevos modelos utilizados, las redes conexionistas aportan una tecnología especialmente adecuada para el tratamiento del problema (p.ej. [Tebelskis & Waibel 90]). También se han utilizado métodos que combinan las redes con algoritmos genéticos [Kitano, 92]. Otros trabajos que han resultado ser muy prometedores se basan en la aplicación de la traducción por analogía, en los que la traducción de una frase se hace en referencia a las traducciones previas de ejemplos similares [Sumita et al., 90]. Un modelo alternativo son las gramáticas de casos, utilizadas originalmente en la comprensión del lenguaje (sec. 1.2.3); en este paradigma se presupone que los casos sirven para representar las sentencias de cualquier lenguaje [Nirenburg et al., 87], siendo entonces innecesario considerar una representación intermedia distinta, que en otros modelos se utiliza para hacer la traducción entre los dos lenguajes. También debemos mencionar el avance que supuso la derivación de dependencias semánticas a partir de las sintácticas, extraídas al considerar los textos de los dos lenguajes (un algoritmo universalmente utilizado al respecto ha sido el de Tomita [Tomita et al., 88]). Un planteamiento muy frecuente es el denominado orientado a la transferencia: se basa en encontrar las correspondencias entre las unidades léxicas y las estructuras sintácticas del lenguaje origen y destino; para ello se retrasa el análisis semántico y pragmático (resolución de elipsis, anáforas, etc.) del origen con vistas a resolver posibles ambigüedades en el destino (p.ej., [Arnold & Sadler, 91]). Se introducen modificaciones en el esquema de interacciones entre el usuario y el sistema. Tradicionalmente la interacción con el usuario sólo se realizaba al principio ¾ preedición¾ o al final del proceso ¾ postedición¾ . Actualmente se considera que es conveniente la participación del usuario en el propio proceso de traducción con el fin de resolver los mayores conflictos. En este caso, según el sistema vaya adquiriendo mayor práctica se irá requiriendo menos ayuda del usuario, hasta una eventual automatización del proceso. Del resto de las tendencias que se observan en el campo podemos destacar: el uso de sistemas de traducción automática como partes de otros sistemas de mayor entidad, la utilización de fuentes alternativas de conocimiento en el proceso ¾ incluido el propio usuario¾ , y la incorporación de elementos multimedia ¾ como lenguaje hablado, imágenes de apoyo, y diagramas¾ .
En lo relativo al reconocimiento de imágenes, un tema que requiere especial atención es la representación espacial. Según se ha descrito [Bobick & Bolles, 89], el problema consiste en intentar integrar la información visual a lo largo del tiempo, según se vaya adquiriendo. El espacio es un proceso continuo de representaciones que van perfilándose con los nuevos datos disponibles. La representación basada en marcos tenían un grave problema de indexación para afrontar este problema, dado que se necesitaba acceder a una gran colección de aquellos. Por ello se optó por utilizar una red de marcos organizada como una red semántica. Una vez más, también en el caso de la interpretación de imágenes, parece sentirse la necesidad de representar el conocimiento mediante una red. A este respecto, cabría preguntarse hasta qué punto un sólo formalismo de representación puede satisfacer los requerimientos de la visión, considerando, por otro lado, que el proceso biológico de la misma parece ser no lineal, variable en el tiempo, jerárquico, y paralelo con un componente secuencial superpuesto [Chellappa & Kashyap, 92]. Un área de máximo interés es cómo puede integrarse un sistema de visión en agentes inteligentes que sean robots móviles (más adelante se analiza el tema de los agentes inteligentes). En cuanto a las necesidades metodológicas del campo podemos destacar que, un área, declarada como de interés especial, es la necesidad de encontrar un marco general en el que se pueda diseñar, describir, experimentar, y documentar experiencias en el reconocimiento de imágenes.
Un área realmente nueva en nuestros días es el de los modelos basados en la computación paralela en gran escala. El origen de las tendencias actuales en este campo fue la llamada máquina conexionista [Hillis, 85]. Es un hecho que los métodos de IA desarrollados hasta ahora dependen en gran medida de los recursos de cálculo disponibles. Parece razonable pensar que el desarrollo de aplicaciones sobre dispositivos de capacidades muy superiores, tendrá consecuencias muy positivas sobre los modelos y sobre el rendimiento de las aplicaciones de IA [Kitano, 93], como lo demuestra los sistemas que ya se están construyendo con estas arquitecturas (p.ej., [Adeli & Park, 96]).
Otro de los principales ùpor no decir, el principalù focos de interés de las investigaciones actuales son los agentes. Podría decirse que si la época anterior era la de los sistemas expertos está es la de los agentes: sistemas de software inteligentes que combinan muchas de las capacidades anteriormente enunciadas: razonar basándose en casos previos, aprender del propio comportamiento y del entorno, entender las intenciones del usuario y adaptarse a sus preferencias, interactuar en un espacio físico concreto, gestionar espacios virtuales de recursos, etc. Realmente, este objetivo es la razón de ser de la IA. La parcelación de este objetivo ha respondido a un principio estratégico básico para enfrentarse a los problemas complejos: "divide y vencerás". En su libro sobre las Teorías Unificadas de la Cognición, Newell [Newell, 90] insistió en la necesidad de redirigir el esfuerzo de investigación en parcelas concretas de la IA hacia concepciones que integraran armonizadamente las soluciones encontradas. Este mismo sentir lo comparten otros investigadores de reconocido prestigio [Hayes-Roth, 93]. Muchas veces las formulaciones de problemas dispares son difícilmente conjugables, llegando a ser, en algunas ocasiones, hasta contradictorias. Por lo tanto, una de las áreas de interés prioritaria debería ser la elaboración de los principios y el diseño de las arquitecturas que sirvan de soporte a esta concepción integrada de la IA. Afortunadamente, se han realizado un número considerable de investigaciones y de aplicaciones comerciales: agentes que solucionan problemas [Hayes-Roth, 85; Newell, 90], sistemas aprendices de ayuda personalizados [Dent et al., 92a, 92b; Etzioni & Weld, 94; Maes, 94], agentes robot [Vere & Bickmore, 90; Firby, 92; Hayes-Roth et al., 95], agentes de problemas de laboratorio [Bresina & Drummond, 90; Pollack, 91], etc. A la vez, se están realizando trabajos paralelos sobre las principales cuestiones que deben resolverse: arquitecturas de agentes [Laird et al., 86; Nilsson, 89; Firby, 92; Hayes-Roth et al., 94], integración de percepción, acción e inferencia [Washington & Hayes-Roth, 89; Chrisman & Simmons, 91], seguimiento de instrucciones [Gans et al., 90; Webber et al., 93], cooperación de múltiples agentes [Sycara, 89; Durfee, 91, Charib-draa et al., 92], etc. La cantidad de estudios que se están realizando refleja el interés que actualmente disfruta este tema. Incluso podemos ya citar agentes cuyo propósito es provocar reacciones en aquellos que forman parte de una audiencia determinada [Bates et al., 95]. Por otro lado, la propia concepción de estos agentes los hace especialmente adecuados para cubrir otra de las áreas de investigación de la IA, la interacción hombre-máquina [Shneiderman, 87]. Finalmente, otro dominio en el que están surgiendo numerosas aplicaciones de estos agentes es la gestión de información y recursos disponibles a través de la red Internet (como queda reflejado en un libro que analiza el elevado número de aplicaciones que ya están operativas en la actualidad [Fah-Chun, 96]).
La definición de cualquier término depende tanto del objetivo que se pretende alcanzar como de los medios que se suponen más adecuados para lograrlo. Por ejemplo, en la sección anterior hemos reinterpretado la historia para encontrar antecedentes de la IA; entre ellos mencionamos un relato sobre el médico Paracelso, que en el siglo XVI elaboró una receta para crear un "homúnculo": un ser humano artificial. Muy posiblemente, para los contemporáneos de Paracelso, la IA sería la rama de la alquimia dedicada a identificar las materias primas y la receta para crear un ser humano.
Dado el contexto del presente análisis, nuestro propósito debe ser analizar el término y sus definiciones dentro del campo de la ciencia de los computadores. Sin lugar a duda, la concepción actual del computador, entendido como medio para alcanzar el objetivo deseado (cuya primera aproximación académica podría ser "creación de inteligencia a partir de métodos realizados por el propio hombre"), condiciona el contenido de las definiciones que aquí vamos a exponer. Otro factor de limitación es el desconocimiento de la esencia de la inteligencia, o si se prefiere, de su estructura. Sólo somos capaces de definirla funcionalmente, por sus capacidades, manifestadas a través del comportamiento del ser humano. El siguiente juego de palabras nos enfrenta a la parte del dilema que tiene que ver con la que consideramos la cualidad esencial de la inteligencia, la capacidad de pensar:
Como también comenta Minsky en otro libro [Minsky, 85], "el problema de la Inteligencia Artificial es la naturaleza de la misma inteligencia, un tema que nadie comprende muy bien. ¿Por qué no? Quizás en parte porque nadie ha tenido la oportunidad de estudiar otros tipos de inteligencia distintos de la humana".
En cualquier caso, el propio proceso de definir siempre es positivo; como dijo el premio Nobel Lwoff: "Definir es uno de los métodos para descubrir". Por tanto, vamos a comprobar, sin más dilación, estos supuestos transcribiendo algunas definiciones de IA:
La mayoría de las definiciones coinciden en que el
objetivo de la IA es duplicar las facultades del comportamiento que atribuimos al ser
humano (aprender, tomar decisiones, percibir, razonar y actuar en consecuencia à),
entendido como ser con capacidad de pensar. Otra definición califica el comportamiento
por su complejidad y no por sus facultades (d). Finalmente, en el resto se omite la
mención de comportamiento alguno (b, g y h). De éstas, la última realiza un precisión
adicional: el objetivo son las cuestiones de solución desconocida. En lo que sí
coinciden todas es en mencionar, implícita o explícitamente, el computador como medio
para lograr dichos objetivos.
Las definiciones de IA responden al carácter científico de esta materia. Como en cualquier otra ciencia (véase la sección 1.3.2), para averiguar las últimas causas, la verdad subyacente, se parte del conocimiento de los fenómenos, en este caso, el comportamiento humano; más exactamente, la capacidad de resolver problemas que requieren inteligencia. Otras ciencias versan sobre la misma materia, la inteligencia, pero bajo distinta fenomenología. La neurología estudia los principios organizacionales y estructurales de los componentes biológicos en los que se genera dicho comportamiento. La ciencia cognitiva se preocupa de los mismos fenómenos desde la perspectiva de los procesos mentales que los producen. En realidad, ambas reflejan dos caminos con un mismo objetivo [Pylshyn, 80]. En el caso de la ciencia cognitiva, la metodología y los modelos son diferentes, ya que en lugar de preocuparse por resolver los problemas mediante modelos computables, se centra en imitar exactamente la forma en que son resueltos por el ser humano.
Considerando lo expuesto, podemos distinguir la doble perspectiva de la IA. Por una lado se considera el objeto de análisis, el comportamiento humano inteligente, y, por otro, el elemento de síntesis, los procesos computables. Por tanto, la IA tiene una componente ciencia de lo natural y otra de ciencia de lo artificial.
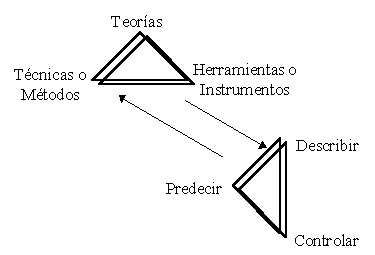
Figura .1: Interrelaciones propias de cualquier rama de la ciencia
Los métodos y técnicas de esta ciencia deben ser traducidos en forma de programas de computador, ya que estos son las máquinas de las que se vale el ser humano actualmente para alcanzar los objetivos señalados. Dada la diversidad de tareas modeladas en este campo, el origen de los métodos utilizados es especialmente variado. Ya hemos señalado como a lo largo de su historia (sec. 1.2) se han utilizado técnicas que provienen de campos como: teoría de la información (p.ej., construcción de árboles de decisión), psicología cognitiva (p.ej., razonamiento basado en casos), investigación operativa (p.ej., métodos de búsqueda como la poda alfa-beta), probabilidad y estadística (p.ej., redes bayesianas), lingüística (p.ej., gramáticas de contexto libre aplicadas en interfaces de lenguaje natural), etc.
Pero todos estos métodos no tendrían sentido si no se supiera cuales son los objetivos. La evolución de las metas, tal y como hemos podido comprobar en el repaso histórico, reflejan un claro proceso de maduración. Utilizando la metáfora de la construcción, podríamos decir que en un principio se pretendió empezar a construir la casa por el tejado. No se tenía consciencia de la complejidad de los pilares de esta ciencia, que requiere solucionar problemas tan diferentes como el reconocimiento de una situación conocida, la coordinación de múltiples tareas y objetivos, el seguimiento de instrucciones, el aprendizaje basado en la observación, etc. En su lugar, se intentaron definir modelos básicos de computación para resolver cualquier tipo de problemas. Más adelante, se tuvo consciencia de la necesidad de utilizar el conocimiento del dominio, y se desarrollaron numerosas técnicas de representación y distintas formas de inferencia. El relativo éxito de estos modelos disparó las expectativas y, por tanto, se incrementaron las inversiones y se promocionó su ingeniería. El también relativo fracaso de estas previsiones ha permitido afrontar uno de los requerimientos básicos de cualquier ciencia aplicada, el establecimiento de una metodología y la clarificación de los objetivos. Era necesario confrontar la diversidad de técnicas desarrolladas y establecer los fundamentos que permitan distinguir su utilidad y sus limitaciones. Actualmente ¾ retomando la metáfora de la construcción¾ , a la vez que se intentan afianzar los pilares de esta hipotética casa, se están empezando a levantar los primeros pisos, los estratos que sirvan para combinar esos cimientos de forma armonizada. Los agentes actuales, los modelos híbridos y multiestrategia del aprendizaje, la cantidad de conferencias de carácter interdisciplinario, la profundización teórica de los modelos utilizados, la utilización y adaptación de métodos de ingeniería del software, son algunas de las manifestaciones de esta nueva realidad que pretende conjugar y asentar las funciones ya modeladas. Por otro lado, la IA sigue siendo la ciencia en la que a todo el mundo le gustaría estar. El objetivo es apasionante y es una ciencia muy viva ¾ como lo demuestra su rápida evolución en el tiempo¾ en la que se deben producir grandes avances. Al fin y al cabo todavía estamos esperando los Newton y Einstein de este campo.
Precisamente, esta rápida evolución determina el
estado actual de las teorías que dan sentido y explican la utilización de los métodos
aplicados. Cualquier ciencia pasa tradicionalmente por una serie de estadios que reflejan
su grado de maduración. Hasta ahora hemos estado inmersos en la época de "los casos
de estudio" o de la experimentación. En esta fase sólo se confirma una hipótesis
de trabajo; por ejemplo, un nuevo método de generalización. La cantidad de experimentos
realizados empieza a permitir dar un nuevo paso, la etapa de los principios
arquitectónicos. En esta nueva fase se busca dar sentido a esa extensión observada para
llegar a ordenar, correlacionar, y construir modelos que la expliquen, pudiendo entonces
plantearse cuestiones como ¿qué métodos deben aplicarse para qué tipo de problemas?.
En la perspectiva aplicada de la IA, la resolución de los problemas consiste en la determinación del método que permite convertir un conjunto de especificaciones funcionales ¾ en este caso referidas al conocimiento¾ en un sistema computable eficaz y eficiente. Como se ha insistido frecuentemente por algunos autores [Mira et al., 95], no debemos olvidar que toda computación termina, por ahora, en el nivel de la electrónica digital. Esto implica que los modelos propios de la IA deben apoyarse en las sucesivas capas que se han definido sobre dicha electrónica (dispositivo, circuito, lógica de circuitos, transferencia-registro, programa, aplicación) con el fin de afrontar la solución de los problemas en un nivel de complejidad cada vez más cercano a la tarea que se quiere resolver. En un principio, las especificaciones de los problemas de IA se realizaban en lenguaje natural. Para intentar simplificar el salto cualitativo que supone convertir dichos requerimientos en un conjunto de procesos descritos mediante un soporte software y hardware concretos, se han establecido niveles genéricos de descripción adicionales que pretenden simplificar las etapas de análisis y diseño propias de cualquier producto de ingeniería.
En primer lugar, debemos mencionar, por importancia y por antigüedad, el nivel del conocimiento [Newell, 81]. En el modelo propuesto por Allen el problema se analiza en dos niveles, uno dependiente del formalismo de representación, nivel simbólico, y otro idealizado, ajeno a cualquier detalle de realización, nivel del conocimiento. La ventaja de este planteamiento es que permite especificar "el qué", cuáles son los objetivos de la tarea, su descripción funcional. Su principal deficiencia es que no sirve para determinar "el cómo", de tal forma que el modelo falla a la hora de predecir el comportamiento del sistema. Sólo los procesos de inferencia que puedan declararse completamente mediante una descripción lógica son los que se pueden precisar en el nivel del conocimiento, en el resto de los sistemas es necesario descender al nivel simbólico para explicar su comportamiento (como se ha podido comprobar en procesos de aprendizaje inductivo [Dietterich, 86]).
Por otro lado, Davis Marr [Marr, 82] introduce, en el contexto de la búsqueda de una teoría computacional de la percepción visual, tres niveles de computación: teoría, algoritmo e implementación. El primer nivel requiere que el problema pueda ser descrito mediante el objetivo de la tarea y la lógica de la estrategia para alcanzarlo; por tanto, coincide con el nivel del conocimiento de Newell. Desgraciadamente, en muchos casos de estudio sólo se dispone de un conjunto impreciso e incompleto de especificaciones funcionales. El segundo nivel, que corresponde al nivel simbólico de Allen, comprende la definición de los espacios simbólicos de representación de las entradas y las salidas y los algoritmos que las enlazan. El tercer nivel se refiere a la especificación del problema en un soporte software que sea traducido automáticamente hasta conectar con el nivel físico. Por tanto, el gran salto sigue encontrándose entre el primero y el segundo nivel.
Los problemas detectados en el proceso de ingeniería de los productos realizados en la primera mitad de los años ochenta (sec. 1.2.3), animaron la búsqueda de nuevos métodos de análisis, diseño, especificación y mantenimiento de sistemas basados en el conocimiento (SBC). La propuesta surgió de dos campos tan interrelacionados como la teoría de modelos y la ingeniería del software. Su principal aportación fue rechazar la idea de que la modelización del conocimiento debía realizarse directamente sobre marcos, reglas, lógica de predicados o cualquiera otra de las técnicas de representación entonces existentes, mucho más cercanas a los modelos computacionales directamente traducibles en código máquina que a los problemas que querían resolverse. En estos casos, muchas descripciones se quedan enfrascadas en resolver problemas relativos al esquema de representación adoptado En su lugar, se propone realizar primero una modelización en la que se distinga claramente el objetivo: la tarea a realizar, y el método: la forma de llevarla a cabo [Chandrasekaran, et al., 92]. Siguiendo esta técnica, a la que se denomina modelo de tareas genéricas, la tarea se estructura en subtareas cada vez más concretas en función del método aplicado en resolverlas. Esto permite, por un lado, estructurar el problema y simplificar su desarrollo y, por otro, compartir, a través del acceso a una librería, tareas y métodos entre diferentes problemas. Además de introducir este nuevo nivel de descripción era necesario estructurar su utilidad en un esquema más general que permitiera integrar el desarrollo del sistema con el resto de los productos realizados con técnicas propias de la ingeniería del software. Esta ha sido precisamente la aportación de KADS [Wielinga et al., 92], una metodología que, estructura el desarrollo de los SBC en dos fases: análisis y diseño, y utiliza el concepto de tarea genérica; pero bajo un enfoque de estructuración del problema invertido, ya que parte de lo más concreto, el modelo del conocimiento del dominio, y va ascendiendo, a través de los modelos de inferencia y tarea genérica, hasta alcanzar el nivel de descripción superior, el de estrategia, cuya función es controlar que se realicen con éxito las tareas necesarias para alcanzar los objetivos seleccionados. Con tal fin se ordenan, planifican o reparan ¾ en caso de fallo¾ , las estructuras de tareas utilizadas. Actualmente, esta metodología incluye, además de la definición del modelo conceptual correspondiente al diseño del sistema, la definición del programa que finalmente será ejecutado [Van de Velde et al., 94].
Hoy en día, la corriente que impera desde el punto de vista metodológico (recordemos que el razonamiento basado en casos parte del mismo supuesto, véase el apartado 1.2.3), sostiene que el conocimiento no puede separarse de su uso [OÆHara & Shadbolt, 93]. Cuando un ingeniero se plantea desarrollar una aplicación basada en el conocimiento, la modelización realizada debe estar orientada al método empleado en su realización. No debe por tanto buscarse un modelo abstracto dependiente de la psicología del experto. El objetivo debe ser establecer los estándares que permitan predecir y controlar las inferencias requeridas. De esta forma, las tareas genéricas son válidas en tanto que facilitan la labor de desarrollo de los SBC, siendo su principal virtud el incrementar la capacidad de describir el problema en el nivel del conocimiento. Para ello se defiende una labor de modelado, ya que mediante este procedimiento se pueden segmentar las partes comunes, identificar procesos de inferencia y predecir resultados a la vez que clarificar interacciones.
Desde el punto de vista metodológico, la IA pretende separar los aspectos estructurales comunes al procedimiento de solución de una clase general de problemas del conocimiento específico de una tarea particular. Este intento no sólo se manifiesta a través de las metodologías basadas en la estructura de tareas genéricas como KADS, sino que también es uno de los objetivos básicos de los nuevos paradigmas híbridos y multiestrategia en el campo del aprendizaje (véase el apartado 1.2.4) y de las llamadas arquitecturas integradas.
Las arquitecturas integradas surgieron para afrontar diversas cuestiones de carácter metodológico. A lo largo del presente análisis hemos mencionado términos como búsqueda, inferencia, representación, organización de memoria y aprendizaje. Pero, ¿cómo podríamos integrar todos estos elementos en un sistema inteligente? El objetivo es el desarrollo de la arquitectura de un agente, capaz de proporcionar un entorno genérico de desarrollo en el cual puedan combinarse dichos elementos. La integración y el diseño de estos macrosistemas tiene sus propios problemas, entre los que destacan: ¿qué métodos de representación, inferencia, etc., deben elegirse?, ¿cuáles son los elementos del diseño que deben representarse explícitamente?, ¿cuáles son los partes más difíciles de solventar y cuales no son abordables?, ¿cuándo y qué debe aprenderse?, ¿qué decisiones de compromiso deben adaptarse?, etc. En realidad, parece claro que hay un espacio propio para la investigación de los problemas de diseño de arquitecturas, sobre el cual todavía quedan muchas cuestiones por resolver. Entre las arquitecturas más conocidas están: SOAR [Laird & Rosenbloom, 90] (posee un mecanismo de generalización implícito), PRODIGY [Carbonell et al., 90] (destaca su capacidad de resolver problemas por analogía), y THEO [Mitchell et al., 91] (utiliza un representación uniforme en la que se confunden tareas de búsqueda, aprendizaje simbólico y conexionista, inferencia lógica, etc.)
Para terminar con este breve repaso sobre los
aspectos metodológicos, dada la importancia que hoy en día tienen los modelos
conexionistas, queremos añadir a lo ya expuesto (sec. 1.2.4)
el análisis de una diferencia clave existente entre el planteamiento simbólico y
conexionista. Cuando la solución de un problema se plantea desde la perspectiva
simbólica, se lleva a cabo un proceso de reducciones sucesivas que depende de la
metodología aplicada. Pensemos en las diversas fases y etapas por las que pasa el
desarrollo de un SBC utilizando la metodología KADS. Sin embargo, cuando la formulación
del problema se modela a través de las llamadas redes neuronales se realiza un salto
directo desde la descripción de la tarea en el nivel del conocimiento hasta un nivel de
procesamiento formado por redes de procesadores cuya función local no puede ser
excesivamente compleja (procesador analógico no lineal seguido de una función no lineal
de tipo sigmoide para limitar las salidas). Frente a esta limitada capacidad de
computación de cada procesador están las ventajas de utilizar una arquitectura de
computación distribuida y de incorporar en el modelo la capacidad de autoprogramación.
La computación neuronal se está convirtiendo en una alternativa para aquellos problemas
que tengan que ver con medios cambiantes y parcialmente conocidos que aconsejen soluciones
paralelas y en tiempo real [Mira et al., 95]. El principal problema es que, dado
que no existen modelos intermedios que faciliten la introducción del conocimiento del
dominio ni la extracción del conocimiento contenido en la red, su aplicación se ve
limitada a aquellas tareas que permiten realizar el salto requerido, como por ejemplo: la
clasificación. No obstante debemos recordar (véase el apartado 1.2.4)
que esta deficiencia está dando lugar a numerosas propuestas basadas en la combinación
de modelos simbólicos y conexionistas.